Overfitting and Underfitting

In the world of machine learning, achieving the perfect model can be a difficult walk. You collect data, train your model, and hope for optimal performance. But often, two formidable foes emerge: overfitting and underfitting.
Overfitting makes your model too sensitive to noise, while underfitting oversimplifies it. These challenges can influence your predictions and lead to costly errors. In this blog post, we'll discuss overfitting and underfitting, uncover their causes, and explore strategies to tackle them.
Overfitting
Overfitting is a common problem in machine learning, where a model learns to fit the training data too closely, capturing not only the underlying patterns but also the noise and randomness present in the data. This results in a model that performs ordinary well on the training data but struggles when faced with new, unseen examples.
Imagine teaching a machine learning model to recognize handwritten digits. If it overfits, it might memorize the specific examples in the training data, effectively "cheating" by not truly understanding the underlying principles of digit recognition. As a consequence, it will fail to generalize to new handwritten digits it hasn't seen before.
Overfitting can be visualized as a model that creates an overly complex decision boundary, trying to accommodate every data point, no matter how noisy or irrelevant. While this may seem like a good thing initially, it often leads to poor performance on real-world data.
Underfitting
In contrast to overfitting, underfitting occurs when a machine learning model is too simplistic to capture the underlying patterns and complexities within the data. This results in a model that not only struggles to perform well on the training data but also performs poorly when presented with new, unseen data.
We can think of underfitting as trying to fit a linear model to data that has non-linear relationships. In such cases, the model's simplicity may lead it to make overly generalized and inaccurate predictions.
For example, if you're building a model to predict housing prices based on various features like square footage, number of bedrooms, and location, an underfit model might assume a linear relationship between square footage and price. This simplistic assumption would overlook the more intricate factors affecting housing prices, resulting in poor predictions.
Underfitting can be visualized as a model that creates an overly simple decision boundary, failing to capture the nuances and variations present in the data. It essentially "underestimates" the data's complexity.
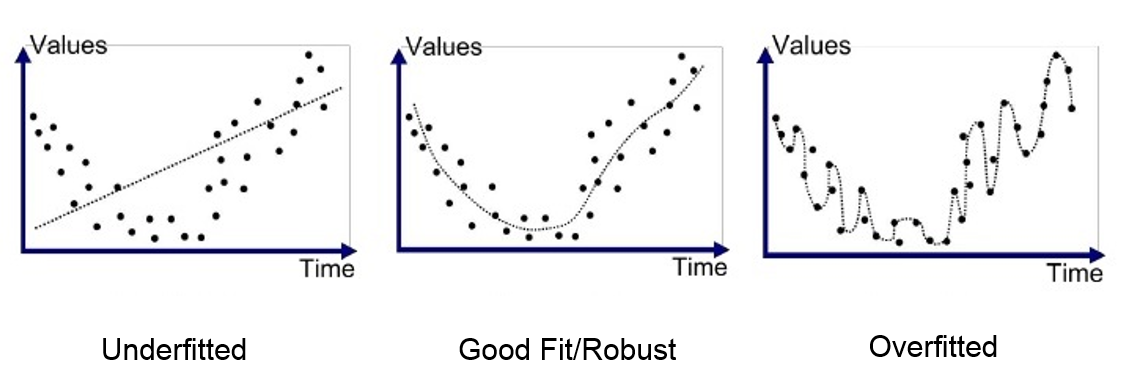
Detection of overfitting and underfitting
Detecting overfitting and underfitting is very important for ensuring the robustness and reliability of our machine learning models. Fortunately, there are several effective methods and techniques to do so:
- Cross-Validation
Cross-validation is a powerful technique that involves splitting your data into multiple subsets for training and testing. By evaluating how well your model performs on different subsets of the data, you can detect signs of overfitting or underfitting. - Learning Curves
Learning curves are graphical representations of a model's performance on the training and validation datasets as a function of the training data size. These curves can help you identify whether your model is overfitting (performing well on training data but not on validation) or underfitting (performing poorly on both training and validation). - Validation Sets
Splitting your data into training and validation sets allows you to monitor the model's performance on unseen data during training. Sudden drops in validation performance while training can indicate overfitting. - Hyperparameter Tuning
Adjusting hyperparameters, such as learning rate, dropout rate, and model complexity, can help find the right balance between underfitting and overfitting. Techniques like grid search or random search can automate this process.
By employing these methods and paying close attention to how our model behaves during training and validation, we can effectively detect signs of overfitting and underfitting, allowing us to take appropriate corrective measures. However, we must continue monitoring the model's performance in production and respond to any signs of unwanted behavior.
Thank you for reading. I hope you enjoyed this article and if there are any questions regarding this topic feel free to drop a comment below. If you want to continue your learning journey with more basics on machine learning have a look at the following article covering the supervised learning method.
 Philipp Zimmermann
Philipp Zimmermann
Citation
If you found this article helpful and would like to cite it, you can use the following BibTeX entry.
@misc{
hacking_and_security,
title={Overfitting and Underfitting},
url={https://hacking-and-security.cc/overfitting-and-underfitting},
author={Zimmermann, Philipp},
year={2024},
month={Jan}
}


